1. 引言 👋
在日常的数据治理过程中,我们经常需要使用到一些自动化工具和编程语言,比如 Python 脚本。
虽然日常数据治理使用 Excel 中的函数、VBA、JS 或 Power Query 功能虽强大,但没有直接支持 Python 的接口,且 JS 和 PQ 对 Excel 的支持还不太友好。
不过最新的 Office 365 base 版本已经内置了 Python 脚本的执行功能,只需要再单元格里面编写 Python 代码即可,但其余的版本暂缓还不能体验到此功能。
因此,本教程将通过一个实际的示例介绍如何使用 Quart 框架来开发 Python RESTful API,利用这样的 API 接收代码片段、编译并执行然后返回数据结果,同时具备基本的错误处理和日志记录功能。
2. 示例介绍 🌟
2.1 示例概述
下面是一个通过 Power Query 调用 Python API 的示例截图,使用了内置的 Web.Contents 和 Json.Document 函数来进行 API 请求和数据的返回。
调用示例
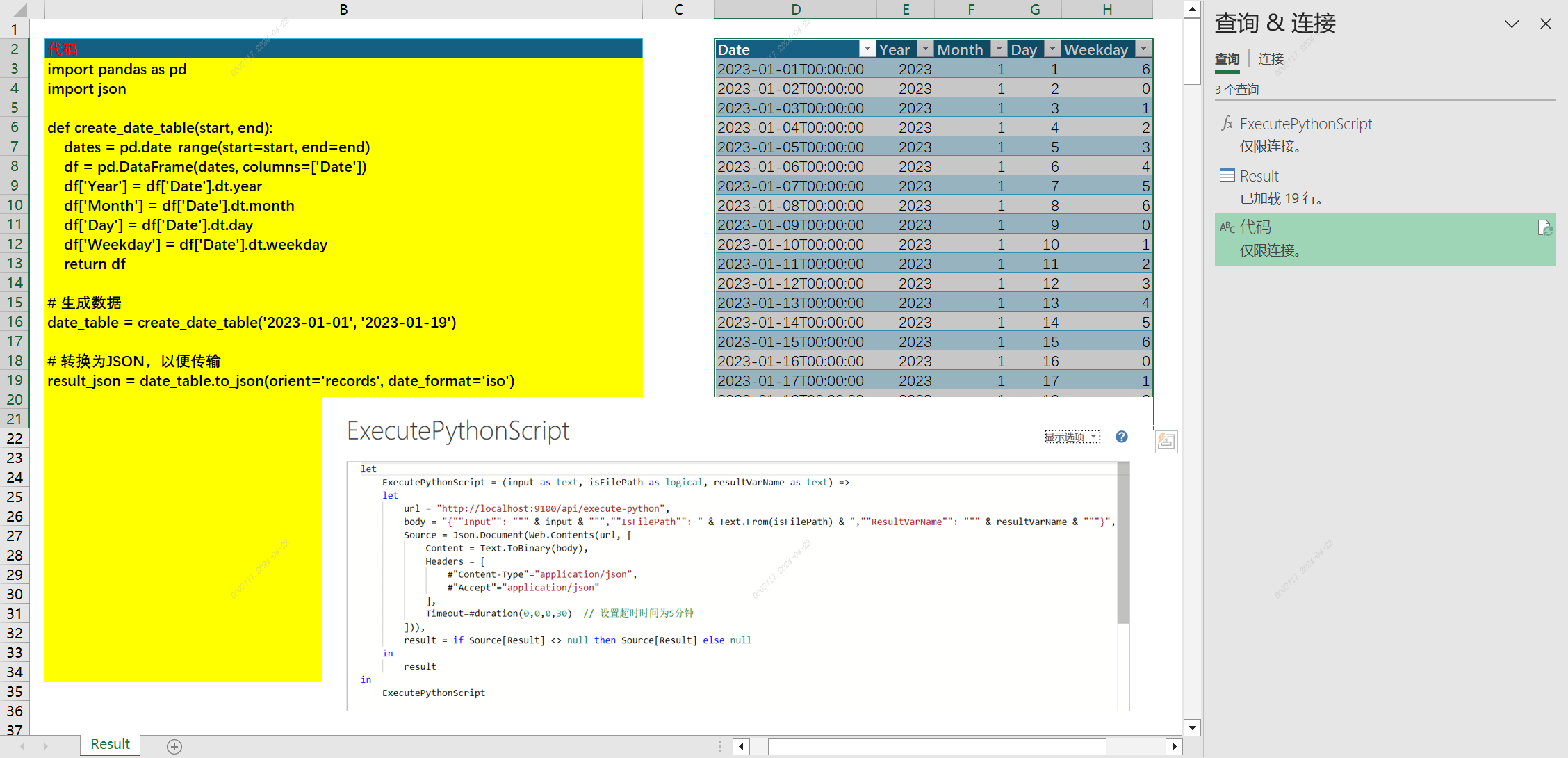
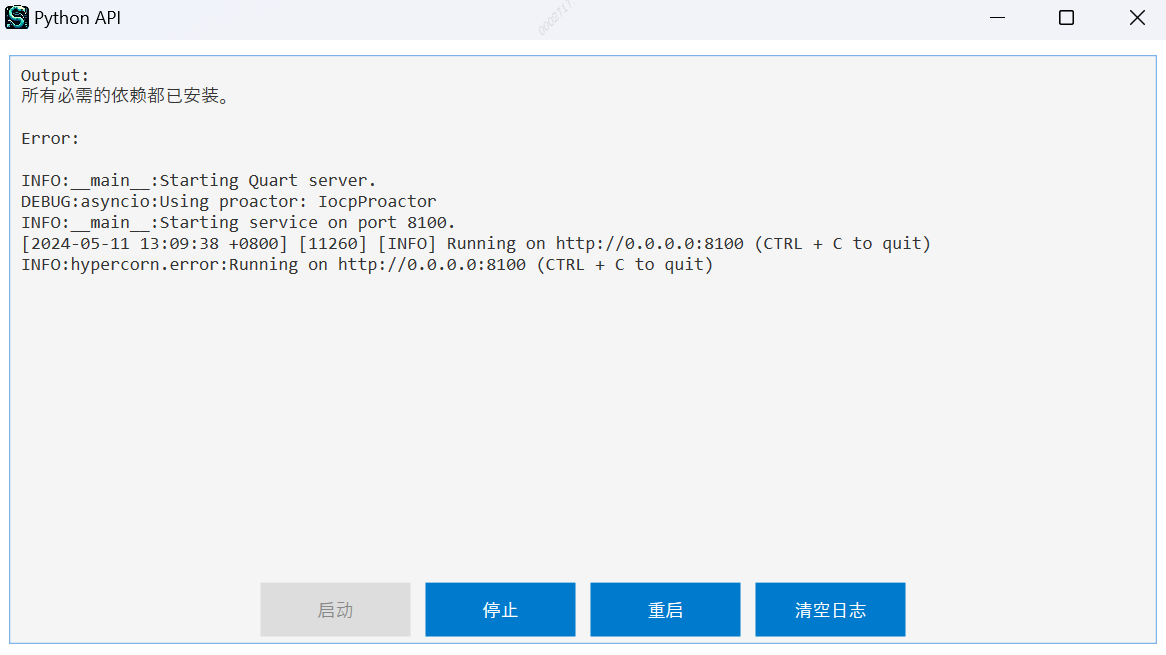
C# 编写的跨平台进程守护主程序
PQ M函数代码
let
ExecutePythonScript = (input as text, isFilePath as logical, resultVarName as text) =>
let
url = "http://localhost:8100/run_python_code",
// 将参数转换为 JSON 字符串并编码为二进制
body = Json.FromValue([code = input, is_path = isFilePath, return_var = resultVarName]),
// 发送 HTTP 请求
Source = Json.Document(Text.FromBinary(Web.Contents(url, [
Content = body,
Headers = [#"Content-Type"="application/json", #"Accept"="application/json"],
Timeout=#duration(0,0,5,0) // 设置超时时间为5分钟
])))
in
Source
in
ExecutePythonScript2.2 完整 Python 代码解析
以下是完整代码,包括了错误处理、日志记录等关键功能的实现。接下来的段落中也会对代码进行相应的解析和讲解。
import traceback
import logging
import json
import ast
from functools import lru_cache
from quart import Quart, request, Response
import os
import logging
from logging.handlers import RotatingFileHandler
import psutil
import subprocess
# 初始化Quart应用
app = Quart(__name__)
# 设置日期存储路径
current_dir = os.path.dirname(os.path.abspath(__file__))
log_file = os.path.join(current_dir, 'app.log')
# 配置日志的基础设置
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = RotatingFileHandler(log_file, maxBytes=10*1024*1024, backupCount=5)
file_handler.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
logging.getLogger('').addHandler(file_handler)
logger = logging.getLogger(__name__)
def check_port_in_use(port):
"""
检查指定端口是否被占用。
Args:
port (int): 要检查的端口号。
Returns:
bool: 如果端口被占用返回 True,否则返回 False。
"""
for conn in psutil.net_connections():
if conn.laddr.port == port:
return True
return False
def stop_service(port):
"""
结束指定端口的服务。
Args:
port (int): 要结束服务的端口号。
"""
subprocess.run(['kill', f'$(lsof -t -i:{port})'])
@app.before_serving
async def before_serving():
"""
在启动服务之前检查端口是否被占用,如果被占用则结束相关服务,并重新启动服务。
"""
if check_port_in_use(8100):
logger.info("Port 8100 is already in use. Stopping previous service.")
stop_service(8100)
logger.info("Starting service on port 8100.")
#start_service()
@lru_cache(maxsize=128)
def compile_code(code):
"""
编译代码,并返回编译后的代码对象以及可能的编译错误信息。
Args:
code (str): 待编译的代码字符串。
Returns:
tuple: 包含编译后的代码对象和可能的编译错误信息的元组。
"""
try:
logger.debug("Compiling code: %s", code)
parsed_code = ast.parse(code, mode='exec')
compiled_code = compile(parsed_code, filename="<string>", mode="exec")
logger.debug("Code compiled successfully")
return compiled_code, None
except SyntaxError as e:
error_info = {
"error_type": type(e).__name__,
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("SyntaxError while compiling code: %s", error_info)
return None, error_info
except Exception as e:
error_info = {
"error_type": type(e).__name__,
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Error while compiling code: %s", error_info)
return None, error_info
@lru_cache(maxsize=128)
def execute_code(compiled_code, return_var):
"""
执行编译后的代码,并返回执行结果以及可能的执行错误信息。
Args:
compiled_code (code): 编译后的代码对象。
return_var (str): 要返回的变量名。
Returns:
tuple: 包含执行结果和可能的执行错误信息的元组。
"""
try:
logger.debug("Executing code")
exec_globals = {}
exec(compiled_code, exec_globals)
result = exec_globals.get(return_var, 'Variable not found') if return_var else 'No result returned or specified'
logger.debug("Code executed successfully")
return result, None
except Exception as e:
error_info = {
"error_type": type(e).__name__,
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Error while executing code: %s", error_info)
return None, error_info
@app.route('/')
async def home():
return Response(json.dumps({"message": "Hello, World!"}), mimetype='application/json'), 200
@app.route('/run_python_code', methods=['POST'])
async def run_python_code():
try:
data = await request.get_data()
data = json.loads(data)
# 验证必要字段是否存在
if 'code' not in data:
raise ValueError("Missing 'code' field in request data")
code = data['code']
return_var = data.get('return_var', None)
# 尝试编译代码
compiled_code, compile_error = compile_code(code)
if compile_error:
response_data = {
"status": "error",
"result": compile_error
}
else:
# 执行代码
result, execution_error = execute_code(compiled_code, return_var)
if execution_error:
response_data = {
"status": "error",
"result": execution_error
}
else:
response_data = {
"status": "success",
"result": result
}
return Response(json.dumps(response_data), mimetype='application/json'), 200
except json.JSONDecodeError as e:
error_info = {
"status": "error",
"error_type": "JSONDecodeError",
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Error while decoding JSON data: %s", error_info)
return Response(json.dumps(error_info), status=400, mimetype='application/json')
except ValueError as e:
error_info = {
"status": "error",
"error_type": "ValueError",
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Error: %s", error_info)
return Response(json.dumps(error_info), status=400, mimetype='application/json')
except Exception as e:
error_info = {
"status": "error",
"error_type": "Internal Server Error",
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Internal Server Error: %s", error_info)
return Response(json.dumps(error_info), status=500, mimetype='application/json')
if __name__ == '__main__':
logger.info("Starting Quart server with dual-stack IPv4/IPv6 support.")
app.run(host='::', port=8100)3. 环境搭建 🛠️
在开始之前,请确保你的开发环境已经安装了 Python 3.7 或更高
版本以及 Quart 框架。
安装 Python
访问 Python 官网下载并安装 Python:Python 官网
安装 Quart 和依赖
打开命令行工具,执行以下命令来安装 Quart 和必要的库:
pip install quart psutil
4. 创建 RESTful API 🛠️
1. 导入“库”模块
为了进行完整的 API 构建和后续的宿主程序等,我们需要导入一些标准库和第三方库的依赖环境,下面是这些模块的一些注释说明。
| 模块/函数 | 功能描述 |
|---|---|
traceback |
用于捕获和打印堆栈跟踪,便于调试时追踪异常。 |
logging |
提供配置日志功能,可以记录应用运行时的各种级别的日志信息。 |
json |
处理JSON数据格式,支持解析JSON字符串和生成JSON格式字符串,用于数据交换。 |
ast |
分析和修改Python代码的抽象语法树,可用于动态代码分析和修改。 |
lru_cache |
提供装饰器用于缓存函数的返回值,避免重复计算,提高效率。 |
Quart |
异步Web框架,用于创建web应用。类似于Flask但支持async/await。 |
request |
处理客户端发送的请求数据。 |
Response |
构造返回给客户端的响应内容。 |
os |
提供了许多与操作系统交互的函数。 |
psutil |
跨平台库(Windows, Linux, OSX, FreeBSD, Sun Solaris等)用于获取系统信息和管理进程。 |
subprocess |
用于产生新进程,连接到它们的输入/输出/错误管道,并获取它们的返回码。 |
代码注释
为了便于理解这里我对导入部分的代码进行了分类并按功能排序,同时添加了注释:
# 标准库导入
import json # JSON 数据处理
import logging # 日志管理
import os # 操作系统接口
import subprocess # 子进程管理
import traceback # 异常跟踪
# 第三方库导入
import psutil # 系统进程和系统利用监控
from quart import Quart, request, Response # Quart Web框架核心
# Python代码处理
import ast # 抽象语法树操作
from functools import lru_cache # 缓存装饰器
# 初始化Quart应用
app = Quart(__name__)2. 日志系统
这段代码是用于创建一个日志系统,方便后续条用 API 时进行排查问题。首先获取脚本路径然后确定日志文件的存储位置,方便进行文件的管理和查看。然后用,logging.basicConfig 设置日志的基础配置,包括日志级别和输出格式。日志级别 DEBUG 意味着会记录所有级别为 DEBUG 及以上的日志信息,这对于开发和测试阶段非常有用。
这里还创建了一个RotatingFileHandler,用于需要长期运行的应用,确保日志文件达到一定大小后自动“轮换”,保存旧文件并创建新文件,避免单个日志文件过大。这里设置了最大文件大小为10MB,然
后最多保留5个备份文件,防止日志文件无限增长。
最后,使用日志记录器 logger,记录颗粒度的日志内容。
# 获取当前脚本所在目录,并确定日志文件的存储位置
current_dir = os.path.dirname(os.path.abspath(__file__))
log_file = os.path.join(current_dir, 'app.log')
# 配置日志的基础设置,包括日志级别和日志格式
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 创建一个旋转日志处理器,设定文件最大10MB,最多保留5个备份
file_handler = RotatingFileHandler(log_file, maxBytes=10*1024*1024, backupCount=5)
file_handler.setLevel(logging.DEBUG) # 设置处理器的日志级别为DEBUG
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter) # 应用日志格式
# 将旋转文件处理器添加到根日志记录器
logging.getLogger('').addHandler(file_handler)
# 创建一个针对当前模块的日志记录器
logger = logging.getLogger(__name__)3. 处理部分的代码说明
这里将通一介绍逻辑处理部分的代码,并简单概述里面的作用。
1. 检查端口是否被占用
def check_port_in_use(port):
"""
检查指定端口是否被占用。
Args:
port (int): 要检查的端口号。
Returns:
bool: 如果端口被占用返回 True,否则返回 False。
"""
for conn in psutil.net_connections():
if conn.laddr.port == port:
return True # 如果发现端口被占用,返回 True
return False # 如果循环结束没有发现端口被占用,返回 False- 这个函数使用
psutil.net_connections()遍历当前系统的所有网络连接。 - 如果找到一个连接的本地地址中的端口与输入的端口号相匹配,表示该端口已被占用,函数返回
True。 - 如果所有连接检查完毕后没有找到占用端口,函数返回
False。
2. 停止占用端口的服务
def stop_service(port):
"""
结束指定端口的服务。
Args:
port (int): 要结束服务的端口号。
"""
subprocess.run(['kill', f'$(lsof -t -i:{port})']) # 执行系统命令强制结束占用端口的进程- 这个函数调用
subprocess.run来执行系统命令。 - 使用
lsof -t -i:{port}命令查找占用指定端口的进程,并通过kill命令结束该进程。
3. 在服务启动前的准备工作
@app.before_serving
async def before_serving():
"""
在启动服务之前检查端口是否被占用,如果被占用则结束相关服务,并重新启动服务。
"""
if check_port_in_use(8100):
logger.info("Port 8100 is already in use. Stopping previous service.")
stop_service(8100)
logger.info("Starting service on port 8100.")
# start_service() # 这行代码被注释了,正常情况下可能会启动服务- 使用装饰器
@app.before_serving标记这个函数会在Quart服务开始监听前执行。 - 函数首先检查端口8100是否被占用,如果是,就记录一条日志并调用
stop_service函数停止占用端口的服务。 - 记录另一条日志,说明服务即将开始在端口8100上启动。
4. 编译代码的函数
@lru_cache(maxsize=128)
def compile_code(code):
"""
编译代码,并返回编译后的代码对象以及可能的编译错误信息。
Args:
code (str): 待编译的代码字符串。
Returns:
tuple: 包含编译后的代码对象和可能的编译错误信息的元组。
"""
try:
logger.debug("Compiling code: %s", code) # 记录正在编译的代码
parsed_code = ast.parse(code, mode='exec') # 使用ast模块解析代码
compiled_code = compile(parsed_code, filename="<string>", mode="exec") # 编译代码
logger.debug("Code compiled successfully") # 记录编译成功的日志
return compiled_code, None
except SyntaxError as e: # 捕获语法错误
error_info = {
"error_type": type(e).__name__,
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("SyntaxError while compiling code: %s", error_info) # 记录错误日志
return None, error_info
except Exception as e: # 捕获其他类型的错误
error_info = {
"error_type": type(e).__name__,
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Error while compiling code: %s", error_info) # 记录错误日志
return None, error_info- 这个函数使用装饰器
@lru_cache(maxsize=128),意味着结果会缓存,重复的请求可以直接使用缓存结果,提高效率。 - 函数尝试编译输入的代码字符串,如果编译成功,则返回编译后的代码对象和
None。 - 如果编译过程中发生错误,比如语法错误,会捕获这个错误并记录,然后返回
None和错误信息。
5. 执行编译后的代码
@lru_cache(maxsize=128)
def execute_code(compiled_code, return_var):
"""
执行编译后的代码,并返回执行结果以及可能的执行错误信息。
Args:
compiled_code (code): 编译后的代码对象。
return_var (str): 要返回的变量名。
Returns:
tuple: 包含执行结果和可能的执行错误信息的元组。
"""
try
logger.debug("Executing code") # 记录正在执行的日志
exec_globals = {} # 创建一个全局变量字典用于exec执行
exec(compiled_code, exec_globals) # 执行编译后的代码
result = exec_globals.get(return_var, 'Variable not found') if return_var else 'No result returned or specified' # 获取返回变量
logger.debug("Code executed successfully") # 记录执行成功的日志
return result, None
except Exception as e: # 捕获执行时的异常
error_info = {
"error_type": type(e).__name__,
"error_message": str(e),
"error_detail": traceback.format_exc()
}
logger.error("Error while executing code: %s", error_info) ### 日志记录错误信息
return None, error_info- 类似于编译函数,这个执行函数也被缓存,以提高相同代码片段的执行效率。
- 使用
exec函数执行编译后的代码,如果指定了返回变量,则尝试从执行的全局字典中获取这个变量的值。 - 如果执行过程中发生异常,会捕获并记录,然后返回错误信息。
缓存大小,如在 lru_cache 装饰器中指定的 maxsize,并不会在一开始就申请并占满这么多的内存空间。而是随着函数调用过程中逐渐填充,直到达到设定的最大数量。缓存的工作原理和内存管理方式是动态的,这里是几个关键点来帮助理解:
4. 缓存工作原理:
偷个懒,上述用到的缓存部分让AI来补充一下👉这个缓存后利于当接口被重复调用或重复处理某个数据集的时候会很有效,可以根据自身数据集的情况来调整大小。
-
按需缓存:
- 当装饰的函数首次被调用时,它的结果将基于传入的参数被计算并存储。随后相同参数的调用将直接从缓存中获取结果,而不是重新计算,从而节省计算资源。
-
缓存大小控制:
maxsize参数定义了缓存可以保存的最大结果数量。一旦存储的结果数量达到这个限制,最旧的结果(最少使用的结果)将被移除,以便为新的结果腾出空间。这是“最近最少使用”(LRU)策略的一部分。
-
内存使用:
- 缓存占用的内存大小取决于存储的数据量和数据类型。
lru_cache并不会预先分配maxsize指定数量的内存,而是根据实际存储的数据动态占用内存。每次调用可能增加内存使用,但仅限于maxsize设定的限制内增长。
- 缓存占用的内存大小取决于存储的数据量和数据类型。
-
内存管理:
- Python 运行时环境会自动管理内存,包括缓存使用的内存。当缓存项因为LRU策略被移除时,如果没有其他引用指向这些对象,这部分内存将被垃圾回收器回收。
因此,lru_cache 提供了一个高效的方式来优化需要重复执行且计算成本高的函数,同时通过限制缓存大小和使用LRU策略来有效管理内存使用,避免过度消耗资源。这种机制特别适合于函数输出完全由输入决定且执行成本较高的情况。
5. 启动并监听端口
我们在入口函数的地方设置了一个日志logger 对象来记录一条信息,说明Quart服务器即将启动。
logger.info("Starting Quart server with dual-stack IPv4/IPv6 support.")然后这里是服务器Quart框架用来启动Web服务器的方法,这里我们设置了支持IPv4和IPv6的双协议栈,方便本地部署和公网服务器等环境部署。
app.run(host='::', port=8100)总结 📚
让AI帮我们总结一下吧!👉本文通过具体的示例和详细的步骤介绍了如何利用 Python 和 Quart 框架构建 RESTful API 来提升数据治理的自动化程度。我们学习了如何在 Excel 中调用这些 API,以及如何编写后端代码来处理请求、执行代码,并返回结果。
关键点回顾:
- Python 的集成: Office 365 base 版本支持在 Excel 中直接编写和执行 Python 脚本,这对于数据分析和自动化尤其有用。
- Quart 框架: 介绍了如何使用 Quart,一个异步的 Web 框架,来构建和部署一个 RESTful API。这对于需要高并发处理的应用程序来说是一个优秀的选择。
- API 的使用: 展示了如何在 Excel 中通过 Power Query 调用自定义的 Python API,实现数据的动态获取和处理。
未来展望:
随着编程语言和工具的不断进化,将编程语言的功能直接集成到办公软件中,为非技术用户提供强大的数据处理能力,已成为一种趋势。未来,我们可以预见到更多的编程功能被集成到各类应用中,使得数据处理和分析更加高效和便捷。
通过本教程,希望你能够理解到 RESTful API 的强大功能,并能够在你的数据治理和分析工作中运用这些技术,以提高工作效率和数据处理能力。
补充
总结的不太好但还行,上述是构建一个API的具体实例,虽然Python几行代码也可以构建一个API应用,但这里是比较具体的实例应用所以相对代码量多了些,如果你有建议或指正欢迎进行补充~
另外关于依赖检查和管理以及宿主程序的开发会在后续的文章内容中讲解~
评论(0)